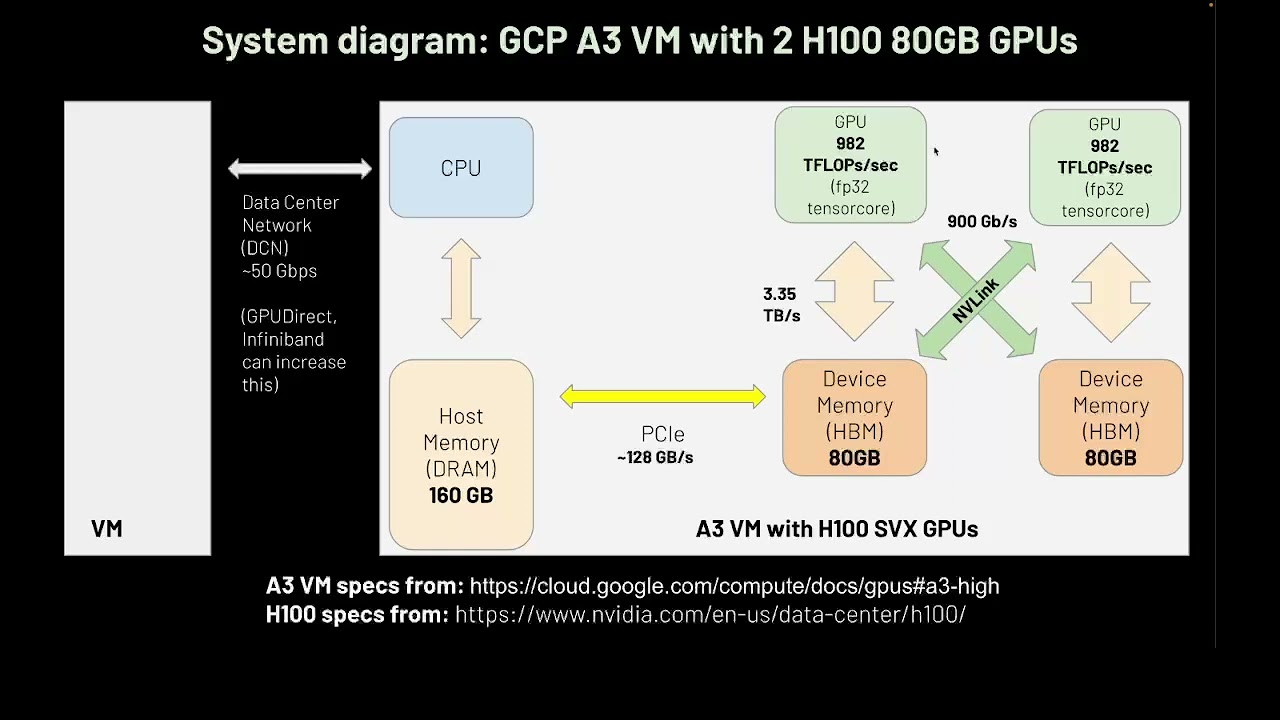
An intro to GPU architecture, CUDA, NCCL, and common ML performance bottlenecks
For session 1 of the EleutherAI ML Scalability & Performance reading group, I gave a presentation covering GPU architecture, CUDA, NCCL, and common ML performance bottlenecks.
We didn’t discuss any research papers in this session; the goal was to go over pre-requisite knowledge to get the most out of reading research papers related to ML scalability and performance.
Recording: