FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
For session 2 of the EleutherAI ML Scalability & Performance reading group, I co-presented a talk on the paper “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.”
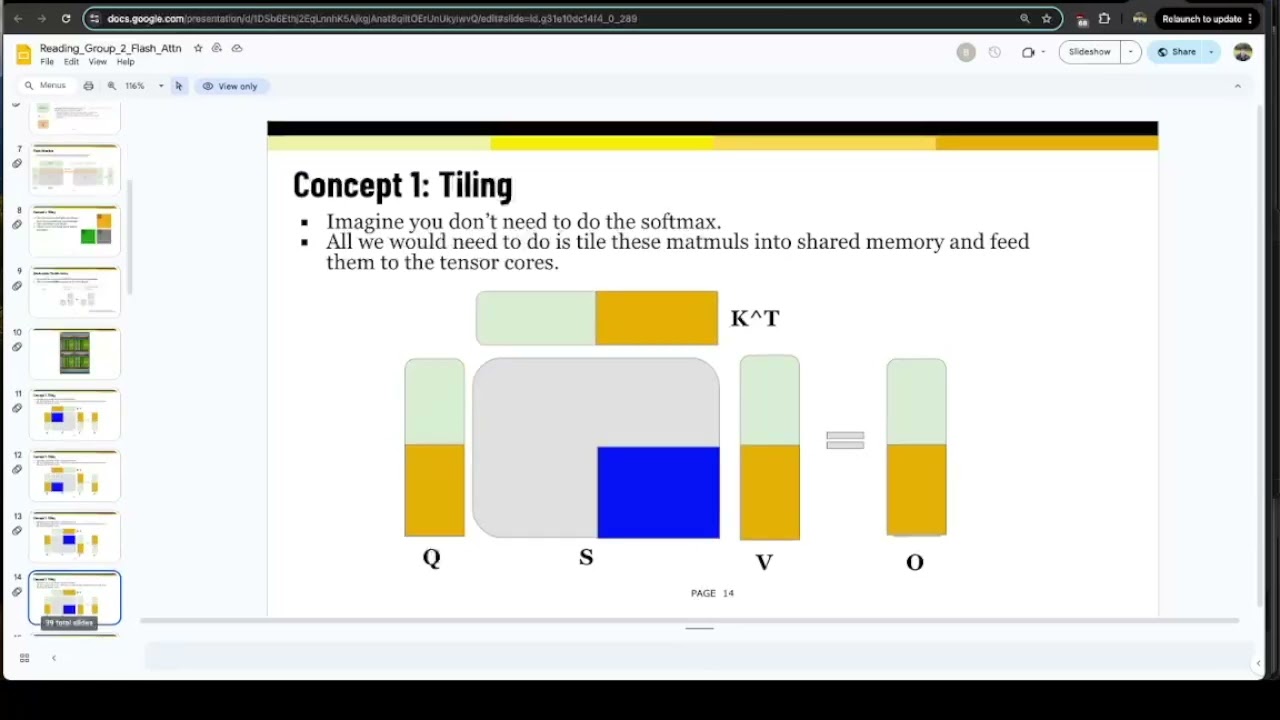
Another member of the reading group (Ben) presented an overview of the theory, and I presented my Triton kernel implementation of Flash Attention 2.
The code can be found here.
Papers:
-
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
-
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Recording: