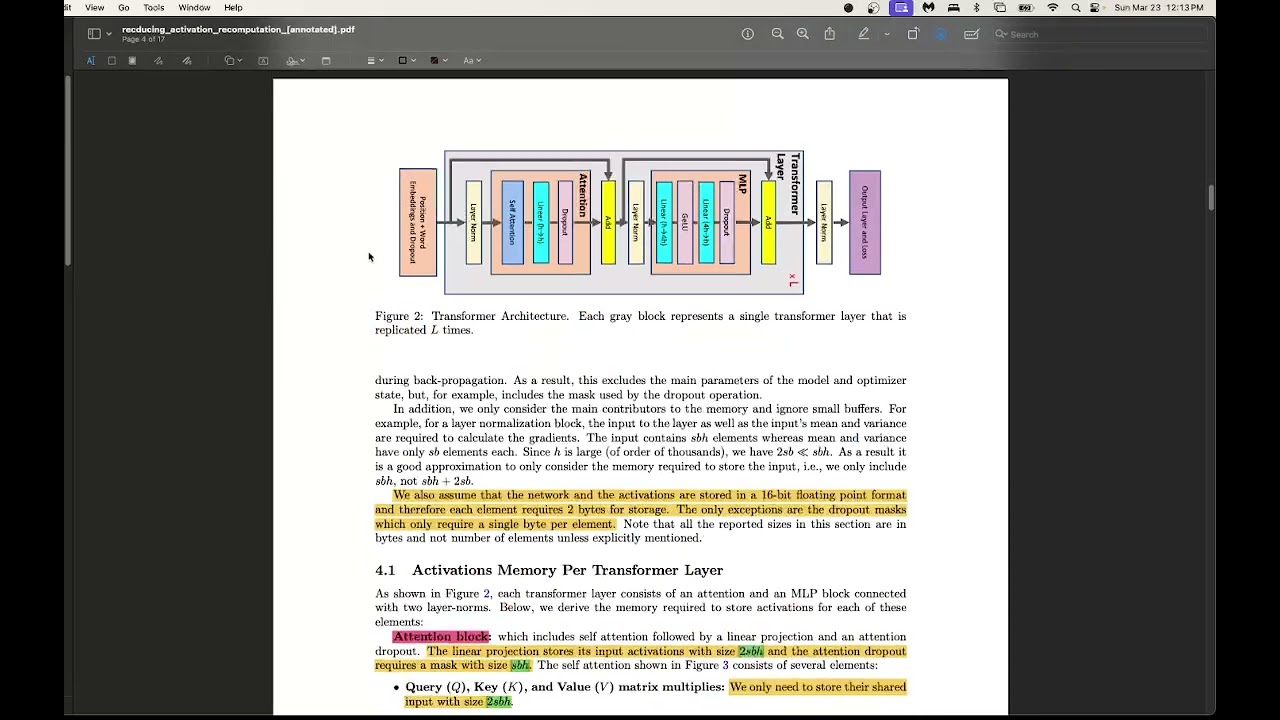
Reducing Activation Recomputation in Large Transformer Models
For session 9 of the Eleuther AI ML Scalability & Performance reading group, I presented the paper “Reducing Activation Recomputation in Large Transformer Models” from NVIDIA, which builds on the tensor parallel strategy introduced in Megatron-LM, with some additional techniques: sequence parallelism and selective activation recomputation.
My annotated versions of these papers can be found be found on my Github here.
Papers:
Recording: